
Technology

Our Challenge
TORmem’s technology enables one memory for all, creating a single high-speed disaggregated memory bank for the whole rack.
To do this, we have to take protocols and technologies that were only designed to operate across a motherboard, and make them operate flawlessly for an entire rack of servers competing for access to the bank of high-speed disaggregated memory that can now be shared amongst them.
This approach makes it possible for the mass market to create systems rivalling a typical supercomputer in performance. Much of the difference between a large or hyperscale server cluster and a standard supercomputer today is the latter’s access to advanced memory access technologies. We aim to democratize this piece of the puzzle, making performance and cost at scale accessible to a whole new class of server operators.
Our products utilize, current and cutting-edge standards designed to provide low-latency, high-bandwidth communication between devices across a motherboard, including PCIe 5.0. Extending this interface across tens of servers in a rack won’t be easy, but we have developed some tricks to help us along the way.
Towards One Memory for All
We believe that creating a single, disaggregated bank of high-speed memory for the entire rack has multiple performance and cost benefits, especially when used at scale, such as:
- The memory supply chain is simplified and scale discounts are easier to obtain
- All servers in the rack can use the latest memory technologies, even over time
- Decommissioned servers will no longer take large amounts of memory with them
- Memory allocation across the rack can be controlled dynamically at a single point
Solving Real Problems
Moore’s Law
As Moore’s Law approaches its limits, and the challenge of processing data locally and regionally becomes more acute due to the volume of data being generated, innovative solutions are required to continue improving performance for new and emerging tasks.
The traditional approach has been to increase the compute capacity of the CPU, and to add more local memory; but this no longer scales. The amount of memory required for many memory-intensive use cases is growing, but the space and cost available for it on each local compute device, such as an individual server is not. How can we solve this?
In-Memory Computing (IMC)
IMC is a model of computing where all of the data required for a particular task to be performed is held within high-speed memory. This is opposed to a model, commonly seen in today’s compute systems whether at small or hyperscale, where there is insufficient high-speed memory to hold all of the data required for a complex task such as machine learning inferencing. This results in the CPU, GPU or other processor needing to wait while data is fetched from a memory or storage source which is orders of magnitude slower than its local RAM, creating performance and efficiency constraints.
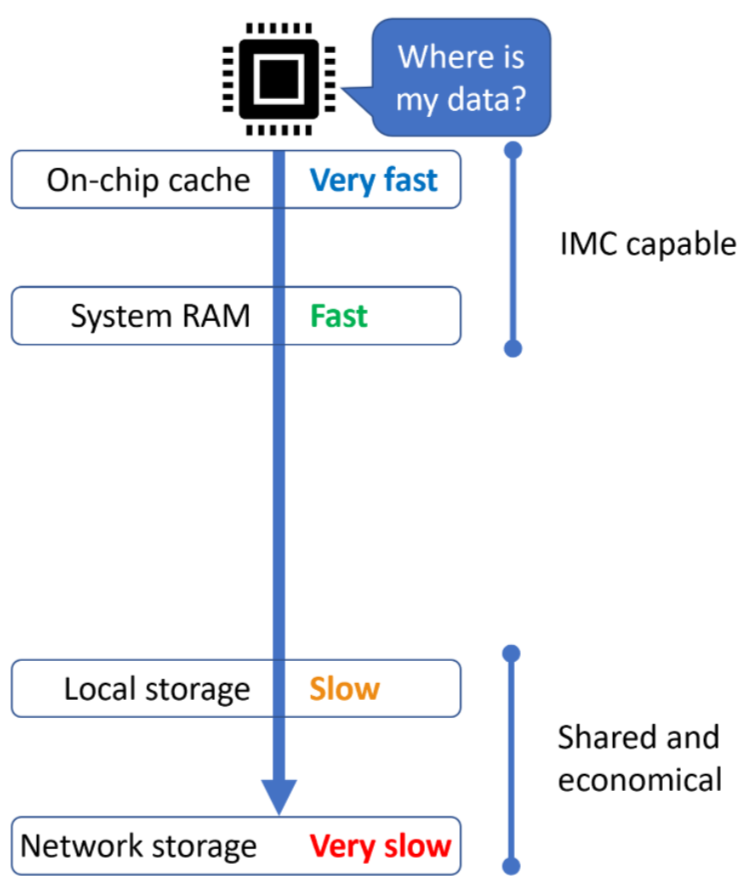
Today’s Compute Systems
In today’s compute systems, it is difficult to outfit an individual server with all of the RAM that it may need due to the technical capabilities of server chipsets including memory access limitations and slot count, as well as economic factors such as uncertainty about where a specific workload may be performed due to the use of abstraction layers common in cloud deployments, which may leave a single server that is over-provisioned with RAM underutilized. The result is a hard choice between small amounts of fast memory which is IMC capable, and large amounts of slow remote memory in the form of storage technologies which are not fast enough to be suitable for IMC.
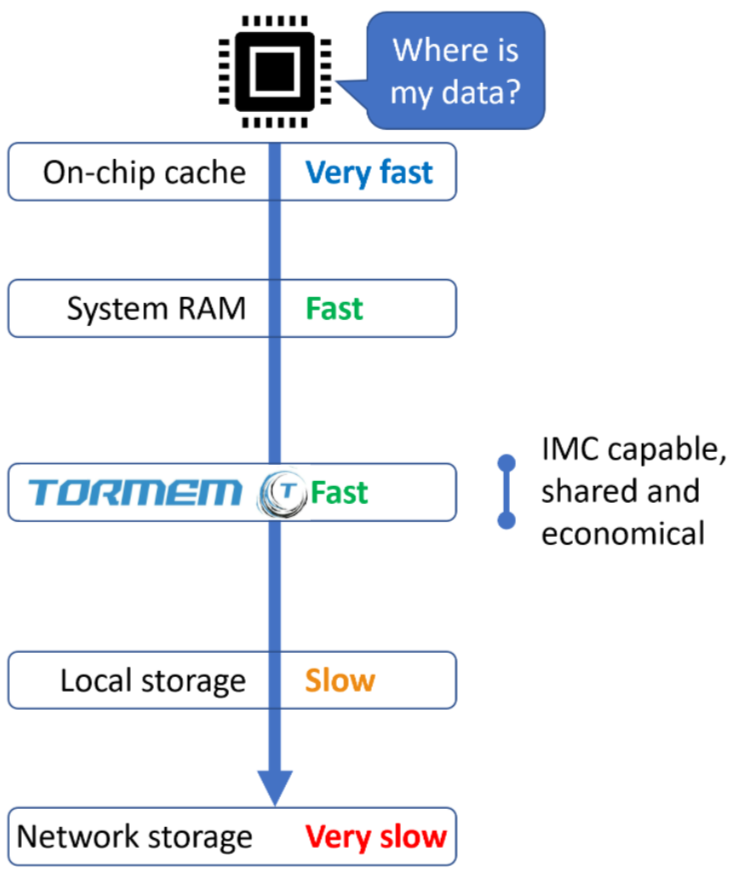
Tomorrow’s Compute Systems
Using TORmem technologies, a new tier of system memory can be added which provides a level of performance that is comparable to local system RAM, but with the same disaggregated, server-remote but rack-local model seen in slower types of memory or storage technologies. The result is a compute system, whether one rack or the combination of hundreds, which is no longer limited by the small capacity and inflexibility of local memory or the sub-par speed of traditional remote memory or storage technologies. The CPU, GPU or any other accelerator can be kept fully fed, allowing new workloads to be supported and for current workloads to operate more efficiently.
Optimizing System Costs
By disaggregating large quantities of local system RAM from each server within the rack, the cost of each individual server can be reduced, as can the impact of its failure on the memory capacity of the entire server cluster. Much like the disaggregation of server storage that the industry has seen, we believe that the disaggregation of memory through our technology will bring about efficiency and design simplicity savings for systems large and small.
Why Disaggregated Memory?
One memory for all. A single disaggregated bank of high-speed memory for the whole rack.
Our technology enables In-Memory Computing (IMC) at data center scale.
Optimize cost, accelerate current workloads, and enable new ones with us.